$\{F_n\}_{n=1}^\infty$
defined by the linear recurrence equation
$$F_n = F_{n-1} + F_{n-2}$$
with $F_1 = F_2 = 1$, and conventionally defining $F_0 = 0$.
We can implement Fibonacci numbers by iteratively or by using recursion. These two functions are implemented in Matlab to compare the running time of the algorithms.
function [result] = fibonacciRecursive(n) %calculates the fibonacci output in recursive way if n==0 || n==1 result=1; else result=fibonacciRecursive(n-1)+ fibonacciRecursive(n-2); end end
function [result] = fibonacciIterative( n ) %calculates the fibonacci output in iterative way y1=1; y2=2; for i=2:n result=y1+y2; y2=y1; y1=result; end end
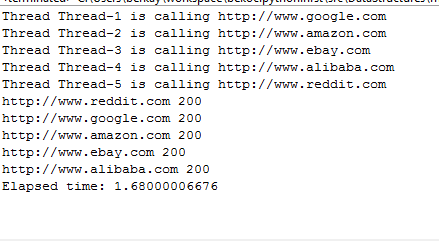
N=10; fibonacciIter=zeros(N,1); fibonacciRecur=zeros(N,1); for i=1:N tic for j=1:25 fibonacciIterative(i); end fibonacciIter(i)=toc; tic for j=1:25 fibonacciRecursive(i); end fibonacciRecur(i)=toc; end X=1:N; plot(X,fibonacciIter,X,fibonacciRecur); legend('Iterative', 'Recursive') xlabel('input size'); ylabel('time(seconds)');

As shown in plot recursive implementation is increasing exponentially in time with the given input size