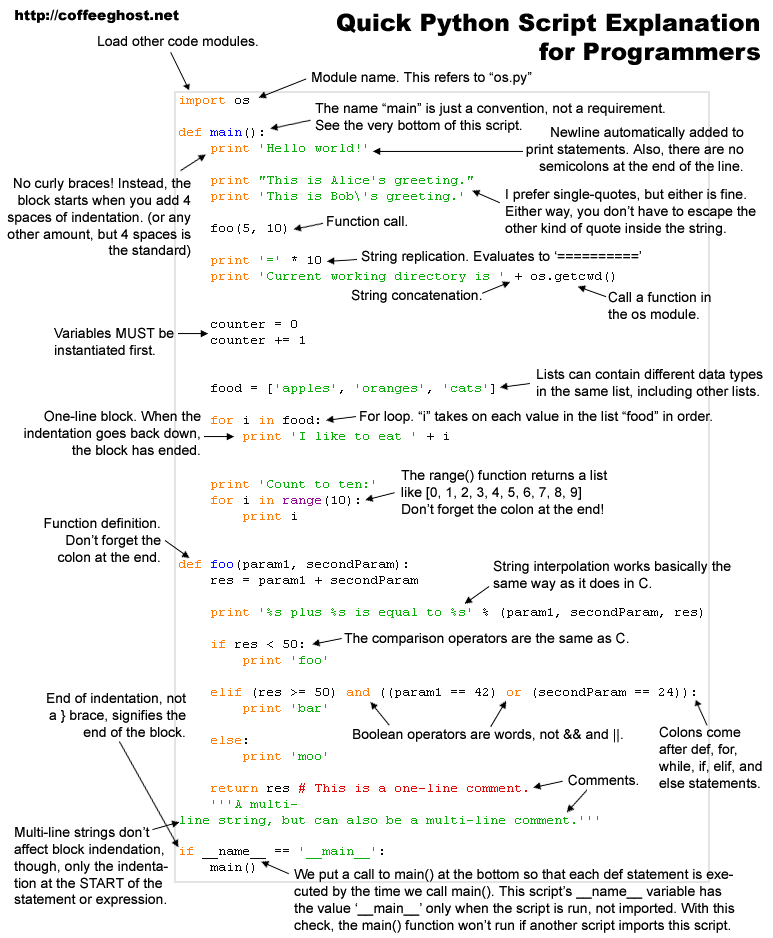
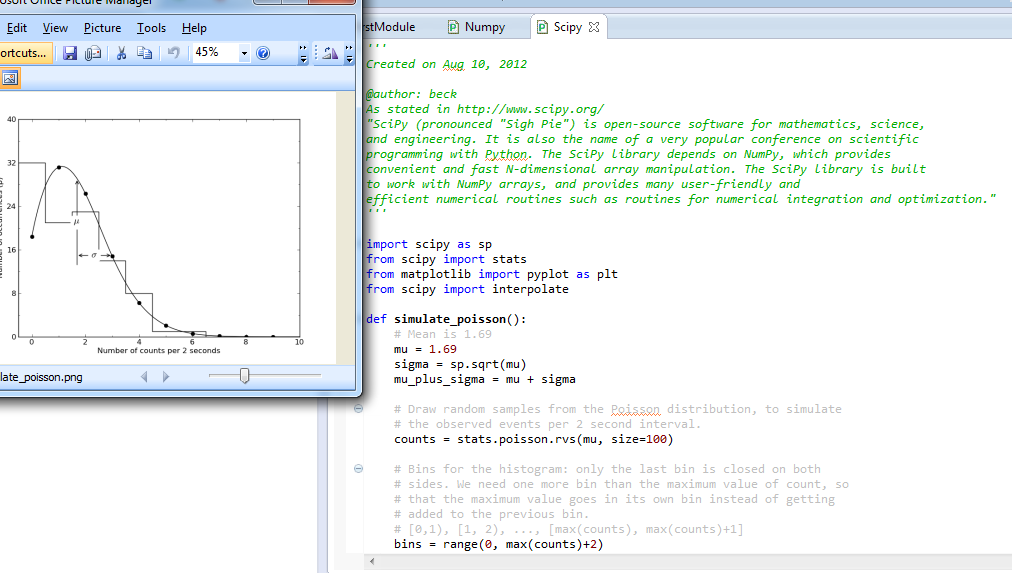
in this post i share my experience while searching about the python machine learning modules. There are lots of them, i think that there is no one that can be used for all algorithms, so for a specific algorithm you can choose one of them that satisfies your need.
First i start reading Scientific Scripting with Python for Computational Immunology, this is the best, short tutorial ever to understand the basic statistics. While going through stackoverflow questions, i realized that many people recommend scikit-learn: machine learning in Python.
i'm familiar with matplotlib and pyplot, however now in examples another module pylab is imported. Clarification: matplotlib, pyplot, and pylab from (http://truongnghiem.wordpress.com):
pyplot is just a wrapper module to provide a Matlab-style interface to matplotlib.Many plotting functions in Matlab are provided by pyplot with the same names and arguments.
This will ease the process of moving from Matlab to Python for scientific computation.pylab is basically a mode in which pyplot and numpy are imported in a single namespace,thus making the Python working environment very similar to Matlab. By importing pylab:
from pylab import *we can use Matlab-style commands like:x = arange(0, 10, 0.2)y = sin(x)plot(x, y)
Dilution Factor,Rep 1,Rep 2,Rep 3,Mean,sdDilution and Factor columns are used in order to implement the linear regression in two dimensional space where the line is defined as :
1,15.16,14.95,14.55,14.89,0.31
2,15.36,15.61,15.51,15.49,0.13
4,16.65,16.88,16.71,16.75,0.12
8,18.07,17.60,18.13,17.93,0.29
16,18.86,19.63,19.39,19.29,0.39
32,20.39,19.40,20.39,20.06,0.57
64,21.44,20.76,21.22,21.14,0.35
128,21.90,22.04,21.94,21.96,0.07
256,22.87,22.77,23.36,23.00,0.32
512,23.98,23.92,24.24,24.05,0.17
1024,24.91,24.83,24.92,24.89,0.05
2048,26.37,25.43,26.21,26.00,0.50
''' *@author beck *@date Sep 14, 2012 *Basic Statistics with Python *bekoc.blogspot.com ''' import numpy import matplotlib.pyplot as plt #import pylab, # from pylab import * import scipy.stats as stats xs= numpy.loadtxt("dilution.csv",delimiter=",", skiprows=1, usecols=(0,1))
# numpy array - similar to C array notation. x= numpy.log2(xs[:,0]) y=xs[:,1] plt.plot(x,y,"x") plt.xlabel('Number of Dilutions(log2)') plt.ylabel('Rep1') plt.title('Linear Regression example') plt.legend() slope, intercept, r_value, p_value, std_error = stats.linregress(x,y) plt.plot(x,intercept+slope*x,"r-") # y=mx+b where m is slope and b is intercept #plt.plot(x,x**2) plt.show()

straight line seems reasonable